Chapter 13 XML: Managing Data Exchange
Words can have no single fixed meaning. Like wayward electrons, they can spin away from their initial orbit and enter a wider magnetic field. No one owns them or has a proprietary right to dictate how they will be used.
David Lehman, End of the Word, 1991
Learning objectives
Students completing this chapter will be able to
define the purpose of XML;
create an XML schema;
code data in XML format;
create an XML stylesheet;
discuss data management options for XML documents.
Four problems
There are four central problems in data management: capture, storage, retrieval, and exchange. The focus for most of this book has been on storage (i.e., data modeling) and retrieval (i.e., SQL). Now it is time to consider capture and exchange. Capture has always been an important issue, and the guiding principle is to capture data once in the cheapest possible manner.
SGML
The Standard Generalized Markup Language (SGML) was designed to reduce the cost and increase the efficiency of document management. Its child, XML, has essentially replaced SGML. For example, the second edition of the Oxford English Dictionary was specified in SGML, and the third edition is stored in XML format.30
A markup language embeds information about a document in the text. In the following example, the markup tags indicate that the text contains CD liner notes. Note also that the titles and identifiers of the mentioned CDs are explicitly identified.
Markup language
<cdliner>This uniquely creative collaboration between
Miles Davis and Gil Evans has already resulted in two
extraordinary albums:
<cdtitle>Miles Ahead</cdtitle><cdid>CL 1041</cdid> and
<cdtitle>Porgy and Bess</cdtitle><cdid>CL 1274</cdid>.
</cdliner>.SGML is an International Standard (ISO 8879) that defines the structure of documents. It is a vendor-independent language that supports cross-system portability and publication for all media. Developed in 1986 to manage software documentation, SGML was widely accepted as the markup language for a number of information-intensive industries. As a metalanguage, SGML is the mother of both HTML and XML.
SGML illustrates four major advantages a markup language provides for data management:
Reuse: Information can be created once and reused over and over. By storing critical documents in markup format, firms do not need to duplicate efforts when there are changes to documents. For example, a firm might store all its legal contracts in SGML.
Flexibility: SGML documents can be published in any medium for a wide variety of audiences. Because SGML is content-oriented, presentation decisions are delayed until the output format is known. Thus, the same content could be printed, presented on the Web in HTML, or written to a DVD as a PDF.
Revision: SGML enhances control over revision and enables version control. When stored in an SGML database, original data are archived alongside any changes. That means you know exactly what the original document contained and what changes were made.
Format independence: SGML files are stored as text and can be read by many programs on all operating systems. Thus, it preserves textual information independent of how and when it is presented. SGML protects a firm’s investment in documentation for the long term. Because it is now possible to display documentation using multiple media (e.g., Web and iPad), firms have become sensitized to the need to store documents in a single, independent manner that can then be converted for display by a particular medium.
SGML’s power is derived from its recording of both text and the meaning of that text. A short section of SGML demonstrates clearly the features and strength of SGML. The tags surrounding a chunk of text describe its meaning and thus support presentation and retrieval. For example, the pair of tags <title> and </title> surrounding “XML: Managing Data Exchange” indicates that it is the chapter title.
SGML code
<chapter>
<no>18</no>
<title>XML: Managing Data Exchange</title>
<section>
<quote><emph type = '2'>Words can have no single fixed meaning.
Like wayward electrons, they can spin away from their initial
orbit and enter a wider magnetic field. No one owns them or has
a proprietary right to dictate how they will be used.</emph>
</quote>
</section>
</chapter>Taking this piece of SGML, it is possible, using an appropriate stylesheet, to create a print version where the title of the chapter is displayed in Times, 16 point, bold, or a HTML version where the title is displayed in red, Georgia, 14 point, italics. Furthermore, the database in which this text is stored can be searched for any chapters that contain “Exchange” in their title.
Now, consider the case where the text is stored as HTML. How do you, with complete certainty, identify the chapter title? Do you extract all text contained by <h1> and </h1> tags? You will then retrieve “18” as a possible chapter title. What happens if there is other text displayed using <h1> and </h1> tags? The problem with HTML is that it defines presentation and has very little meaning. A similar problem exists for documents prepared with a word processor.
HTML code
<html>
<body>
<h1><b>18 </b></h1>
<h1><b>XML: Managing Data Exchange</b></h1>
<p><i>Words can have no single fixed meaning.
Like wayward electrons, they can spin away from their
initial orbit and enter a wider magnetic field.
No one owns them or has a proprietary right to
dictate how they will be used.</i>
</body>
</html>By using embedded tags to record meaning, SGML makes a document platform-independent and greatly improves the effectiveness of searching. Despite its many advantages, there are some features of SGML that make implementation difficult and also limit the ability to create tools for information management and exchange. As a result, XML, a derivative of SGML, was developed.
XML
Extensible Markup Language (XML), a language designed to make information self-describing, retains the core ideas of SGML. You can think of XML as SGML for electronic commerce. Since the definition of XML was completed in early 1998 by the World Wide Web Consortium (W3C), the standard has spread rapidly because it solves a critical data management problem. XML is a metalanguage—a language to generate languages.
Despite having the same parent, there are major differences between XML and HTML.
XML vs. HTML
| XML | HTML |
|---|---|
| Structured text | Formatted text |
| User-definable structure (extensible) | Predefined formats (not extensible) |
| Context-sensitive retrieval | Limited retrieval |
| Greater hypertext linking | Limited hypertext linking |
HTML, an electronic-publishing language, describes how a Web browser should display text and images on a computer screen. It tells the browser nothing about the meaning of the data. For example, the browser does not know whether a piece of text represents a price, a product code, or a delivery date. Humans infer meaning from the context (e.g., August 8, 2012, is recognized as a date). Given the explosive growth of the Web, HTML clearly works well enough for exchanging data between computers and humans. It does not, however, work for exchanging data between computers, because computers are not smart enough to deduce meaning from context.
Successful data exchange requires that the meaning of the exchanged data be readily determined by a computer. The XML solution is to embed tags in a file to describe the data (e.g., insert tags into an order to indicate attributes such as price, size, quantity, and color). A browser, or program for that matter, can then recognize this document as a customer order. Consequently, it can do far more than just display the price. For example, it can convert all prices to another currency. More importantly, the data can be exchanged between computers and understood by the receiving system.
XML consists of rules (that anyone can follow to create a markup language (e.g., a markup language for financial data such as XBRL). Hence, the “eXtensible” in the XML name, indicating that the language can be easily extended to include new tags. In contrast, HTML is not extensible and its set of tags is fixed, which is one of the major reasons why HTML is easy to learn. The XML rules ensure that a type of computer program known as a parser can process any extension or addition of new tags.
XML rules
Elements must have both an opening and a closing tag.
Elements must follow a strict hierarchy with only one root element.
Elements must not overlap other elements.
Element names must obey XML naming conventions.
XML is case sensitive.
Consider the credit card company that wants to send you your latest statement via the Internet so that you can load it into your financial management program. Since this is a common problem for credit card companies and financial software authors, these industry groups have combined to create Open Financial Exchange (OFX), a language for the exchange of financial data across the Internet.
XML has a small number of rules. Tags always come in pairs, as in HTML. A pair of tags surrounds each piece of data (e.g., <price>89.12</price>) to indicate its meaning, whereas in HTML ,they indicate how the data are presented. Tag pairs can be nested inside one another to multiple levels, which effectively creates a tree or hierarchical structure. Because XML uses Unicode (see the discussion in Chapter 20), it enables the exchange of information not only between different computer systems, but also across language boundaries.
The differences between HTML and XML are captured in the following examples for each markup language. Note that in the following table, HTML incorporates formatting instructions (i.e., the course code is bold), whereas XML describes the meaning of the data.
Comparison of HTML and XML coding
| HTML | XML |
|---|---|
| <p><b>MIST7600</b> | <course> |
| Data Management<br> | <code>MIST7600</code> |
| 3 credit hours</p> | <title>Data Management</title> |
| </course> | <credit>3</credit> |
XML enables a shift of processing from the server to the browser. At present, most processing has to be done by the server because that is where knowledge about the data is stored. The browser knows nothing about the data and therefore can only present but not process. However, when XML is implemented, the browser can take on processing that previously had to be handled by the server.
Imagine that you are selecting a shirt from a mail-order catalog. The merchant’s Web server sends you data on 20 shirts (100 Kbytes of text and images) with prices in U.S. dollars. If you want to see the prices in euros, the calculation will be done by the server, and the full details for the 20 shirts retransmitted (i.e., another 100 Kbytes are sent from the server to the browser). However, once XML is in place, all that needs to be sent from the server to the browser is the conversion rate of U.S. dollars to euros and a program to compute the conversion at the browser end. In most cases, less data will be transmitted between a server and browser when XML is in place. Consequently, widespread adoption of XML will reduce network traffic.
Execution of HTML and XML code
| HTML | XML |
|---|---|
| Retrieve shirt data with prices in USD. | Retrieve shirt data with prices in USD. |
| Retrieve shirt data with prices in EUR. | Retrieve conversion rate of USD to EUR |
| Retrieve script to convert currencies. | |
| Compute prices in EUR. |
XML can also make searching more efficient and effective. At present, search engines look for matching text strings, and consequently return many links that are completely irrelevant. For instance, if you are searching for details on the Nomad speaker system, and specify “nomad” as the sought text string, you will get links to many items that are of no interest (e.g., The Fabulous Nomads Surf Band). Searching will be more precise when you can specify that you are looking for a product name that includes the text “nomad.” The search engine can then confine its attention to text contained with the tags <productname> and </productname>, assuming these tags are the XML standard for representing product names.
The major expected gains from the introduction of XML are
Store once and format many ways—Data stored in XML format can be extracted and reformatted for multiple presentation styles (e.g., PDF, ePUB).
Hardware and software independence—One format is valid for all systems. Capture once and exchange many times—Data are captured as close to the source as possible and never again (i.e., no rekeying).
Accelerated targeted searching—Searches are more precise and faster because they use XML tags.
Less network congestion—The processing load shifts from the server to the browser.
XML language design
XML lets developers design application-specific vocabularies. To create a new language, designers must agree on three things:
The allowable tags
The rules for nesting tagged elements
Which tagged elements can be processed
The first two, the language’s vocabulary and structure, are typically defined in an XML schema. Developers use the XML schema to understand the meaning of tags so they can write software to process an XML file.
XML tags describe meaning, independent of the display medium. An XML stylesheet, another set of rules, defines how an XML file is automatically formatted for various devices. This set of rules is called an Extensible Stylesheet Language (XSL). Stylesheets allow data to be rendered in a variety of ways, such as Braille or audio for visually impaired people.
XML schema
An XML schema (or just schema for brevity) is an XML file associated with an XML document that informs an application how to interpret markup tags and valid formats for tags. The advantage of a schema is that it leads to standardization. Consistently named and defined tags create conformity and support organizational efficiency. They avoid the confusion and loss of time when the meaning of data is not clear. Also, when validation information is built into a schema, some errors are detected before data are exchanged.
XML does not require the creation of a schema. If a document is well formed, XML will interpret it correctly. A well-formed document follows XML syntax and has tags that are correctly nested.
A schema is a very strict specification, and any errors will be detected when parsing. A schema defines:
The names and contents of all elements that are permissible in a certain document
The structure of the document
How often an element may appear
The order in which the elements must appear
The type of data the element can contain
DOM
The Document Object Model (DOM) is the model underlying XML. It is based on a tree (i.e., it directly supports one-to-one and one-to-many, but not many-to-many relationships). A document is modeled as a hierarchical collection of nodes that have parent/child relationships. The node is the primary object and can be of different types (such as document, element, attribute, text). Each document has a single document node, which has no parent, and zero or more children that are element nodes. It is a good practice to create a visual model of the XML document and then convert this to a schema, which is XML’s formal representation of the DOM.
At this point, an example is the best way to demonstrate XML, schema, and DOM concepts. We will use the familiar CD problem that was introduced in Chapter 3. In keeping with the style of this text, we define a minimal amount of XML to get you started, and then more features are added once you have mastered the basics.
CD library case
The CD library case gradually develops, over several chapters, a data model for recording details of a CD collection, culminating in the model at the end of Chapter 6. Unfortunately, we cannot quickly convert this final model to an XML document model, because a DOM is based on a tree model. Thus, we must start afresh.
The model , in this case, is based on the observation that a CD library has many CDs, and a CD has many tracks.
CD library tree data model
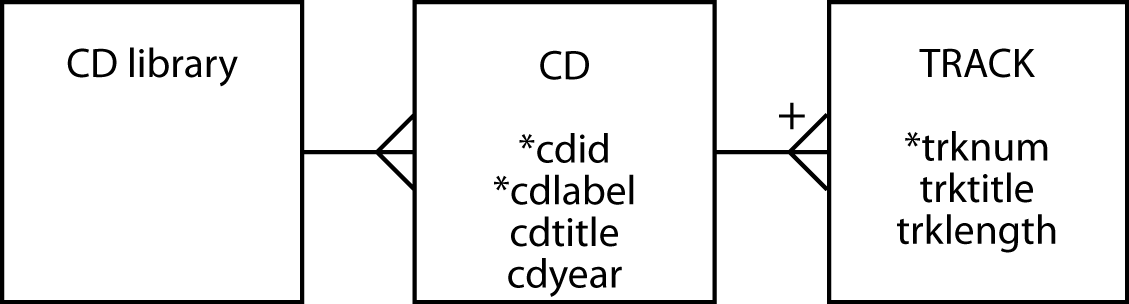
A model is then mapped into a schema using the following procedure.
Each entity becomes a complex element type.
Each data model attribute becomes a simple element type.
The one-to-many (1:m) relationship is recorded as a sequence.
The schema for the CD library follows. For convenience of exposition, the source code lines have been numbered, but these numbers are not part of a schema.31
Schema for CD library (cdlib.xsd)
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns:xsd='http://www.w3.org/2001/XMLSchema'>
<!--CD library-->
<xsd:element name="cdlibrary">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="cd" type="cdType" minOccurs="1"
maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<!--CD-->
<xsd:complexType name="cdType">
<xsd:sequence>
<xsd:element name="cdid" type="xsd:string"/>
<xsd:element name="cdlabel" type="xsd:string"/>
<xsd:element name="cdtitle" type="xsd:string"/>
<xsd:element name="cdyear" type="xsd:integer"/>
<xsd:element name="track" type="trackType" minOccurs="1"
maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<!--Track-->
<xsd:complexType name="trackType">
<xsd:sequence>
<xsd:element name="trknum" type="xsd:integer"/>
<xsd:element name="trktitle" type="xsd:string"/>
<xsd:element name="trklen" type="xsd:time"/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>There are several things to observe about the schema.
All XML documents begin with an XML declaration {1}.32 The encoding attribute (i.e., encoding=“UTF-8”) specifies what form of Unicode is used (in this case the 8-bit form).
The XSD Schema namespace33 is declared {2}.
Comments are placed inside the tag pair <!– and –> {3}.
The CD library is defined {4–10} as a complex element type, which essentially means that it can have embedded elements, which are a sequence of CDs in this case.
A sequence is a series of child elements embedded in a parent, as illustrated by a CD library containing a sequence of CDs {7}, and a CD containing elements of CD identifier, label, and so forth {15–20}. The order of a sequence must be maintained by any XML document based on the schema.
A sequence can have a specified range of elements. In this case, there must be at least one CD (minOccurs=“1”) but there is no upper limit (maxOccurs= “unbounded”) on how many CDs there can be in the library {7}.
An element that has a child (e.g., cdlibrary, which is at the 1 end of a 1:m) or possesses attributes (e.g., track) is termed a complex element type.
A CD is represented by a complex element type {13–20}, and has the name cdType {13}.
The element cd is defined by specifying the name of the complex type (i.e., cdType) containing its specification {7}.
A track is represented by a complex type because it contains elements of track number, title, and length {24–30}. The name of this complex type is trackType {24}.
Notice the reference within the definition of cd to the complex type trackType, used to specify the element track {19}.
Simple types (e.g., cdid and cdyear) do not contain any elements, and thus the type of data they store must be defined. Thus, cdid is a text string and cdyear is an integer.
The purpose of a schema is to define the contents and structure of an XML file. It is also used to verify that an XML file has a valid structure and that all elements in the XML file are defined in the schema.
If you use an editor, you can possibly create a visual view of the schema.
A visual depiction of a schema as created by Oxygen
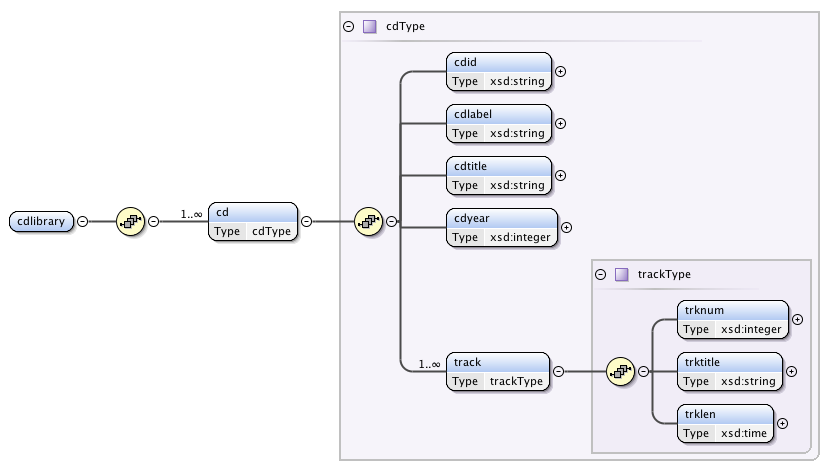
Some common data types are shown in the following table. The meaning is obvious in most cases for those familiar with SQL, except for uriReference. A Uniform Resource Identifier (URI) is a generalization of the URL concept.
Some common data types
Data type string boolean anyURI decimal float integer time date We can now use the recently defined CDlibrary schema to describe a small CD library containing the CD information given in the following table.
Data for a small CD library
The XML for describing the CD library follows. There are several things to observe:
All XML documents begin with an XML declaration.
The declaration immediately following the XML declaration identifies the root element of the document (i.e., cdlibrary) and the schema (i.e., cdlib.xsd).
Details of a CD are enclosed by the tags <cd> and </cd>.
Details of a track are enclosed by the tags <track> and </track>.
XML for describing a CD (cdlib.xml)
<?xml version="1.0" encoding="UTF-8"?> <cdlibrary xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="cdlib.xsd"> <cd> <cdid>A2 1325</cdid> <cdlabel>Atlantic</cdlabel> <cdtitle>Pyramid</cdtitle> <cdyear>1960</cdyear> <track> <trknum>1</trknum> <trktitle>Vendome</trktitle> <trklen>00:02:30</trklen> </track> <track> <trknum>2</trknum> <trktitle>Pyramid</trktitle> <trklen>00:10:46</trklen> </track> </cd> <cd> <cdid>D136705</cdid> <cdlabel>Verve</cdlabel> <cdtitle>Ella Fitzgerald</cdtitle> <cdyear>2000</cdyear> <track> <trknum>1</trknum> <trktitle>A tisket, a tasket</trktitle> <trklen>00:02:37</trklen> </track> <track> <trknum>2</trknum> <trktitle>Vote for Mr. Rhythm</trktitle> <trklen>00:02:25</trklen> </track> <track> <trknum>3</trknum> <trktitle>Betcha nickel</trktitle> <trklen>00:02:52</trklen> </track> </cd> </cdlibrary>As you now realize, the definition of an XML document is relatively straightforward. It is a bit tedious with all the typing of tags to surround each data element. Fortunately, there are XML editors that relieve this tedium.
❓ Skill builder
Use the Chrome browser to access this book’s Web site XML page, and click on customerpayments.xml. You
will see how this browser displays XML. Investigate what happens when you click on the grey triangles next to some entries.Again, using Chrome, save the displayed XML code (Save Page As …) as customerpayments.xml, and open it in a text editor.
Now, add details of the customer and payment data displayed in the following table to the beginning of the XML file. Open the saved file with Chrome, and verify your work.
Customer and payment data
AA Souvenirs, Yallingup, Western Australia
Check number Amount Date QP45901 9387.45 2005-03-16 AG9984 3718.67 2005-07-24 XSL
As you now know from the prior exercise, the browser display of XML is not particularly useful. What is missing is a stylesheet that tells the browser how to display an XML file. The eXtensible Stylesheet Language (XSL) is used for defining the rendering of an XML file. An XSL document defines the rules for presenting an XML document’s data. XSL is an application of XML, and an XSL file is also an XML file.
The power of XSL is demonstrated by applying the stylesheet that follows to the preceding XML.
Result of applying a stylesheet to CD library data
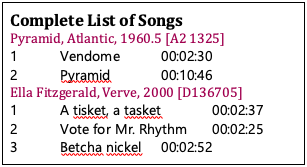
Stylesheet for displaying an XML file of CD data (cdlib.xsl)
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output encoding="UTF-8" indent="yes" method=“html" /> <xsl:template match="/"> <html> <head> <title> Complete List of Songs </title> </head> <body> <h1> Complete List of Songs </h1> <xsl:apply-templates select="cdlibrary" /> </body> </html> </xsl:template> <xsl:template match="cdlibrary"> <xsl:for-each select="cd"> <br/> <font color="maroon"> <xsl:value-of select="cdtitle" /> , <xsl:value-of select="cdlabel" /> , <xsl:value-of select="cdyear" /> [ <xsl:value-of select="cdid" /> ] </font> <br/> <table> <xsl:for-each select="track"> <tr> <td align="left"> <xsl:value-of select="trknum" /> </td> <td> <xsl:value-of select="trktitle" /> </td> <td align="center"> <xsl:value-of select="trklen" /> </td> </tr> </xsl:for-each> </table> <br/> </xsl:for-each> </xsl:template> </xsl:stylesheet>To use a stylesheet with an XML file, you must add a line of code to point to the stylesheet file. In this case, you add the following:
<?xml-stylesheet type=”text/xsl” href=”cdlib.xsl” media=”screen”?>as the second line of cdlib.xml (i.e., it appears before <cdlibrary … >). The added line of code points to cdlib.xsl as the stylesheet. This means that when the browser loads cdlib.xml, it uses the contents of cdlib.xsl to determine how to render the contents of cdlib.xml.
We now need to examine the contents of cdlib.xsl so that you can learn some basics of creating XSL commands. You will soon notice that all XSL commands are preceded by xsl:
Tell the browser it is processing an XML file {1}
Specify that the file is a stylesheet {2}
Specify a template, which identifies which elements should be processed and how they are processed. The match attribute {4} indicates the template applies to the source node. Process the template {11} defined in the file {15–45}. A stylesheet can specify multiple templates to produce different reports from the same XML input.
Specify a template to be applied when the XSL processor encounters the <cdlibrary> node {15}.
Create an outer loop for processing each CD {16–44}.
Define the values to be reported for each CD (i.e., title, label, year, and id) {19, 21, 23, 25}. The respective XSL commands select the values. For example, <xsl:value-of select=“cdtitle”/> specifies selection of cdtitle.
Create an inner loop for processing the tracks on a particular CD {29–41}.
Present the track data in tabular form using HTML table commands interspersed with XSL {28–42}.
❓ Skill builder
Use the Chrome browser to access this book’s Web site, navigate to the XML page, and download cdlib.xml and cdlib.xsl to a directory or folder on your machine. Use Save Page As … for downloading.
Using a text editor, change the saved copy of cdlib.xml by inserting the following as the second line:
<?xml-stylesheet type=“text/xsl” href=“cdlib.xsl” media=“screen”?>Save the edited file in the same directory or folder as cdlib.xsl. Open the saved XML file with Chrome.
Converting XML
There are occasions when there is a need to convert an XML file:
Transformation: conversion from one XML vocabulary to another (e.g., between financial languages FPML and finML)
Manipulation: reordering, filtering, or sorting parts of a document
Rendering in another language: rendering the XML file using another format
You have already seen how XSL can be used to transform XML for rendering as HTML. The original XSL has been split into three languages:
XSLT for transformation and manipulation
XSLT for rendition
XPath for accessing the structure of an XML file
For a data management course, this is as far as you need to go with learning about XSL. Just remember that you have only touched the surface. To become proficient in XML, you will need an entire course on the topic.
XPath for navigating an XML document
XPath is a navigation language for an XML document. It defines how to select nodes or sets of nodes in a document. The first step to understanding XPath is to know about the different types of nodes. In the following XML document, the document node is <cdlibrary> {1}, <trktitle>Vendome</trktitle> {9} is an example of an element node, and <track length=“00:02:30”> {7} is an instance of an attribute node.
An XML document
<cdlibrary> <cd> <cdid>A2 1325</cdid> <cdlabel>Atlantic</cdlabel> <cdtitle>Pyramid</cdtitle> <cdyear>1960</cdyear> <track length="00:02:30"> <trknum>1</trknum> <trktitle>Vendome</trktitle> </track> <track length="00:10:46"> <trknum>2</trknum> <trktitle>Pyramid</trktitle> </track> </cd> </cdlibrary>A family of nodes
Each element and attribute has one parent node. In the preceding XML document, cd is the parent of cdid, cdlabel, cdyear, and track. Element nodes may have zero or more children nodes. Thus cdid, cdlabel, cdyear, and track are the children of cd. Ancestor nodes are the parent, parent’s parent, and so forth of a node. For example, cd and cdlibrary are ancestors of cdtitle. Similarly, we have descendant nodes, which are the children, children’s children, and so on of a node. The descendants of cd include cdid, cdtitle, track, trknum, and trktitle. Finally, we have sibling nodes, which are nodes that share a parent. In the sample document, cdid, cdlabel, cdyear, and track are siblings.
Navigation examples
The examples in the following table give you an idea of how you can use XPath to extract data from an XML document. Our preference is to answer such queries using SQL, but if your data are in XML format, then XPath provides a means of interrogating the file.
XPath examples
Example Result /cdlibrary/cd[1] Selects the first CD //trktitle Selects all the titles of all tracks /cdlibrary/cd[last() -1] Selects the second last CD /cdlibrary/cd[last()]/track[last()]/trklen T he length of the last track on the last CD /cdlibrary/cd[cdyear=1960] Selects all CDs released in 1960 /cdlibrary/cd[cdyear>1950]/cdtitle Titles of CDs released after 1950 XQuery for querying an XML document
XQuery is a query language for XML, and thus it plays a similar role that SQL plays for a relational database. It is used for finding and extracting elements and attributes of an XML document. It builds on XPath’s method for specifying navigation through the elements of an XML document. As well as being used for querying, XQuery can also be used for transforming XML to XHTML.
The first step is to specify the location of the XML file. In this case, we will use the cdlib.xml file, which is stored on the web site for this book. Using XPath notation it is relatively straightforward to list some values in an XML file
List the titles of CDs.
doc("http://www.richardtwatson.com/xml/cdlib.xml")/cdlibrary/cd/cdtitle <?xml version="1.0" encoding="UTF-8"?> <cdtitle>Pyramid</cdtitle> <cdtitle>Ella Fitzgerald</cdtitle>You can also use an XPath expression to select particular information.
List the titles of CDs released under the Verve label
doc("http://www.richardtwatson.com/xml/cdlib.xml")/cdlibrary/cd[cdlabel='Verve']/cdtitle <?xml version="1.0" encoding="UTF-8"?> <cdtitle>Ella Fitzgerald</cdtitle>XQuery commands can also be written using an SQL like structure, which is called FLWOR, an easy way to remember ‘For, Let, Where, Order by, Return.’ Here is an example.
List the titles of tracks longer than 5 minutes
for $x in doc("http://www.richardtwatson.com/xml/cdlib.xml")/cdlibrary/cd/track where $x/'track length' > "00:05:00" order by $x/'trktitle' return $x <?xml version="1.0" encoding="UTF-8"?> <track> <trknum>2</trknum> <trktitle>Pyramid</trktitle> <trklen>00:10:46</trklen> </track>If you want to just report the data without the tags, use return data($x).
Conclusion
XML has two main roles. The first is to facilitate the exchange of data between organizations and within those organizations that do not have integrated systems. Its second purpose is to support exchange between servers.
Mastery of XML is well beyond the scope of a single chapter. Indeed, it is a book-length topic, and hundreds of books have been written on XML. It is important to remember that the prime goal of XML is to support data interchange. If you would like to continue learning about XML, then consider the open content textbook (en.wikibooks.org/wiki/XML), which was created by students and is under continual revision. You might want to contribute to this book.
Summary
Electronic data exchange became more important with the introduction of the Internet. SGML, a precursor of XML, defines the structure of documents. SGML’s value derives from its reusability, flexibility, support for revision, and format independence. XML, a derivative of SGML, is designed to support electronic commerce and overcome some of the shortcomings of SGML. XML supports data exchange by making information self-describing. It is a metalanguage because it is a language for generating other languages (e.g., finML). It provides substantial gains for the management and distribution of data. The XML language consists of an XML schema, document object model (DOM), and XSL. A schema defines the structure of a document and how an application should interpret XML markup tags. The DOM is a tree-based data model of an XML document. XSL is used to specify a stylesheet for displaying an XML document.
Key terms and concepts
Document object model (DOM) Markup language Document type definition (DTD) Occurrence indicators Electronic data interchange (EDI) Standard generalized markup language (SGML) Extensible markup language (XML) XML database Extensible stylesheet language (XSL) XML schema Hypertext markup language (HTML) References and additional readings
Watson, R. T., and others. 2004. XML: managing data exchange.
Exercises
A business has a telephone directory that records the first and last name, telephone number, and e-mail address of everyone working in the firm. Departments are the main organizing unit of the firm, so the telephone directory is typically displayed in department order, and shows for each department the contact phone and fax numbers and e-mail address.
Create a hierarchical data model for this problem.
Define the schema.
Create an XML file containing some directory data.
Create an XSL file for a stylesheet and apply the transformation to the XML file.
Create a schema for your university or college’s course bulletin.
Create a schema for a credit card statement.
Create a schema for a bus timetable.
Using the portion of ClassicModels that has been converted to XML, answer the following questions using XPath.
List all customers.
Who is the last customer in the file?
Select all customers in Sweden.
List the payments of more than USD 100,000.
Select the first payments by Toys4GrownUps.com.
What was the payment date for check DP677013?
Who paid with check DP677013?
What payments were received on 2003-12-04?
Who made payments on 2003-12-04?
List the numbers of all checks from customers in Denmark.
Using the portion of ClassicModels that has been converted to XML, answer the following questions using XQuery.
List all customers.
Who is the last customer in the file?
Select all customers in Sweden sorted by customer name.
List the payments of more than USD 100,000.
Select the first payments by Toys4GrownUps.com.
What was the payment date for check DP677013?
Who paid with check DP677013?
What payments were received on 2003-12-04?
Who made payments on 2003-12-04?
List the numbers of all checks from customers in Denmark.
Cowlishaw, M. F. (1987). Lexx—a programmable structured editor. IBM Journal of Research and Development, 31(1), 73-80.↩︎
You should use an XML editor for creating XML files. I have not found a good open source product. Among the commercial products, my preference is for Oxygen, which you can get for a 30 days trial.↩︎
In this chapter, numbers in {} refer to line numbers in the corresponding XML code.↩︎
A namespace is a collection of valid names of attributes, types, and elements for a schema. Think of a namespace as a dictionary.↩︎