Chapter 23 Data Integrity
Integrity without knowledge is weak and useless, and knowledge without integrity is dangerous and dreadful.
Samuel Johnson, Rasselas, 1759
Learning objectives
After completing this chapter, you will - understand the three major data integrity outcomes; - understand the strategies for achieving each of the data integrity outcomes; - understand the possible threats to data integrity and how to deal with them; - understand the principles of transaction management; - realize that successful data management requires making data available and maintaining data integrity.
Introduction
The management of data is driven by two goals: availability and integrity. Availability deals with making data available to whomever needs it, whenever and wherever he or she needs it, and in a meaningful form. As illustrated in following figure, availability concerns the creation, interrogation, and update of data stores. Although most of the book, thus far, has dealt with making data available, a database is of little use to anyone unless it has integrity. Maintaining data integrity implies three goals:56
Protecting existence: Data are available when needed.
Maintaining quality: Data are accurate, complete, and current.
Ensuring confidentiality: Data are accessed only by those authorized to do so.
Goals of managing organizational memory
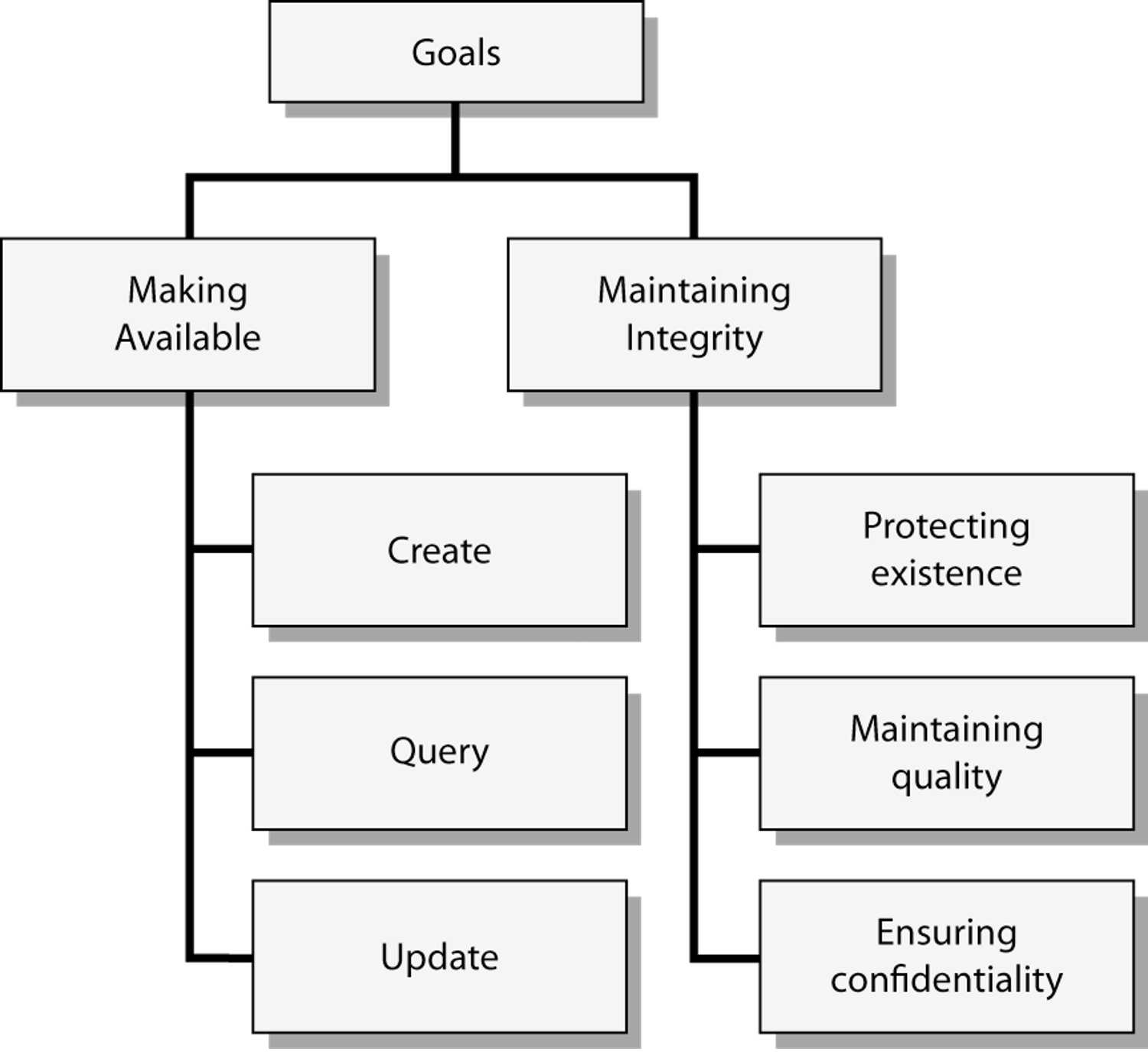
This chapter considers the three types of strategies for maintaining data integrity:
Legal strategies are externally imposed laws, rules, and regulations. Privacy laws are an example.
Administrative strategies are organizational policies and procedures. An example is a standard operating procedure of storing all backup files in a locked vault.
Technical strategies are those incorporated in the computer system (e.g., database management system, application program, or operating system). An example is the inclusion of validation rules (e.g., NOT NULL) in a database definition that are used to ensure data quality when a database is updated.
A consistent database is one in which all data integrity constraints are satisfied.
Our focus is on data stored in multiuser computer databases and technical and administrative strategies for maintaining integrity in computer system environments., commonly referred to as database integrity. More and more, organizational memories are being captured in computerized databases. From an integrity perspective, this is a very positive development. Computers offer some excellent mechanisms for controlling data integrity, but this does not eliminate the need for administrative strategies. Both administrative and technical strategies are still needed.
Who is responsible for database integrity? Some would say the data owners, others the database administrator. Both groups are right; database integrity is a shared responsibility, and the way it is managed may differ across organizations. Our focus is on the tools and strategies for maintaining data integrity, regardless of who is responsible.
The strategies for achieving the three integrity outcomes are summarized in the following table. We will cover procedures for protecting existence, followed by those for maintaining integrity, and finally those used to ensure confidentiality. Before considering each of these goals, we need to examine the general issue of transaction management.
Strategies for maintaining database integrity
| Database integrity outcome | Strategies for achieving the outcome |
|---|---|
| Protecting existence | Isolation (preventive) |
| Database backup and recovery (curative) | |
| Maintaining quality | Update authorization |
| Integrity constraints/data validation | |
| Concurrent update control | |
| Ensuring confidentiality | Access control |
| Encryption |
Transaction management
Transaction management focuses on ensuring that transactions are correctly recorded in the database. The transaction manager is the element of a DBMS that processes transactions. A transaction is a series of actions to be taken on the database such that they must be entirely completed or entirely aborted. A transaction is a logical unit of work. All its elements must be processed; otherwise, the database will be incorrect. For example, with a sale of a product, the transaction consists of at least two parts: an update to the inventory on hand, and an update to the customer information for the items sold in order to bill the customer later. Updating only the inventory or only the customer information would create a database without integrity and an inconsistent database.
Transaction managers are designed to accomplish the ACID (atomicity, consistency, isolation, and durability) concept. These attributes are:
Atomicity: If a transaction has two or more discrete pieces of information, either all of the pieces are committed or none are.
Consistency: Either a transaction creates a valid new database state or, if any failure occurs, the transaction manager returns the database to its prior state.
Isolation: A transaction in process and not yet committed must remain isolated from any other transaction.
Durability: Committed data are saved by the DBMS so that, in the event of a failure and system recovery, these data are available in their correct state.
Transaction atomicity requires that all transactions are processed on an all-or-nothing basis and that any collection of transactions is serializable. When a transaction is executed, either all its changes to the database are completed or none of the changes are performed. In other words, the entire unit of work must be completed. If a transaction is terminated before it is completed, the transaction manager must undo the executed actions to restore the database to its state before the transaction commenced (the consistency concept). Once a transaction is successfully completed, it does not need to be undone. For efficiency reasons, transactions should be no larger than necessary to ensure the integrity of the database. For example, in an accounting system, a debit and credit would be an appropriate transaction, because this is the minimum amount of work needed to keep the books in balance.
Serializability relates to the execution of a set of transactions. An interleaved execution schedule (i.e., the elements of different transactions are intermixed) is serializable if its outcome is equivalent to a non-interleaved (i.e., serial) schedule. Interleaved operations are often used to increase the efficiency of computing resources, so it is not unusual for the components of multiple transactions to be interleaved. Interleaved transactions cause problems when they interfere with each other and, as a result, compromise the correctness of the database.
The ACID concept is critical to concurrent update control and recovery after a transaction failure.
Concurrent update control
When updating a database, most applications implicitly assume that their actions do not interfere with any other’s actions. If the DBMS is a single-user system, then a lack of interference is guaranteed. Most DBMSs, however, are multiuser systems, where many analysts and applications can be accessing a given database at the same time. When two or more transactions are allowed to update a database concurrently, the integrity of the database is threatened. For example, multiple agents selling airline tickets should not be able to sell the same seat twice. Similarly, inconsistent results can be obtained by a retrieval transaction when retrievals are being made simultaneously with updates. This gives the appearance of a loss of database integrity. We will first discuss the integrity problems caused by concurrent updates and then show how to control them to ensure database quality.
Lost update
Uncontrolled concurrent updates can result in the lost-update or phantom-record problem. To illustrate the lost-update problem, suppose two concurrent update transactions simultaneously want to update the same record in an inventory file. Both want to update the quantity-on-hand field (quantity). Assume quantity has a current value of 40. One update transaction wants to add 80 units (a delivery) to quantity, while the other transaction wants to subtract 20 units (a sale).
Suppose the transactions have concurrent access to the record; that is, each transaction is able to read the record from the database before a previous transaction has been committed. This sequence is depicted in the following figure. Note that the first transaction, A, has not updated the database when the second transaction, B, reads the same record. Thus, both A and B read in a value of 40 for quantity. Both make their calculations, then A writes the value of 120 to disk, followed by B promptly overwriting the 120 with 20. The result is that the delivery of 80 units, transaction A, is lost during the update process.
Lost update when concurrent accessing is allowed
| Time | Action | Database record | ||
|---|---|---|---|---|
| Part# | Quantity | |||
| P10 | 40 | |||
| T1 | App A receives message for delivery of 80 units of P10 | |||
| T2 | App A reads the record for P10 | ← | P10 | 40 |
| T3 | App B receives message for sale of 20 units of P10 | |||
| T4 | App B reads the record for P10 | ← | P10 | 40 |
| T5 | App A processes delivery (40 + 80 = 120) | |||
| T6 | App A updates the record for P10 | → | P10 | 120 |
| T7 | App B processes the sale of (40 - 20 = 20) | |||
| T8 | App B updates the record P10 | → | P10 | 20 |
Inconsistent retrievals occur when a transaction calculates some aggregate function (e.g., sum) over a set of data while other transactions are updating the same data. The problem is that the retrieval may read some data before they are changed and other data after they are changed, thereby yielding inconsistent results.
The solution: locking
To prevent lost updates and inconsistent retrieval results, the DBMS must incorporate a resource lock, a basic tool of transaction management to ensure correct transaction behavior. Any data retrieved by one application with the intent of updating must be locked out or denied access by other applications until the update is completed (or aborted).
There are two types of locks: Slocks (shared or read locks) and Xlocks (exclusive or write locks). Here are some key points to understand about these types of locks:
When a transaction has a Slock on a database item, other transactions can issue Slocks on the same item, but there can be no Xlocks on that item.
Before a transaction can read a database item, it must be granted a Slock or Xlock on that item.
When a transaction has an Xlock on a database item, no other transaction can issue either a Slock or Xlock on that item.
Before a transaction can write to a database item, it must be granted an Xlock on that item.
Consider the example used previously. When A accesses the record for update, the DBMS must refuse all further accesses to that record until transaction A is complete (i.e., an Xlock). As the following figure shows, B’s first attempt to access the record is denied until transaction A is finished. As a result, database integrity is maintained. Unless the DBMS controls concurrent access, a multiuser database environment can create both data and retrieval integrity problems.
Valid update when concurrent accessing is not allowed
| Time | Action | Database record | ||
|---|---|---|---|---|
| Part# | Quantity | |||
| P10 | 40 | |||
| T1 | App A receives message for delivery of 80 units of P10 | |||
| T2 | App A reads the record for P10 | ← | P10 | 40 |
| T3 | App B receives message for sale of 20 units of P10 | |||
| T4 | App B attempts to read the record for P10 | deny | P10 | 40 |
| T5 | App A process delivery (40 + 80 = 120) | |||
| T6 | App A updates the record for P10 | → | P10 | 120 |
| T7 | App B reads the record for P10 | ← | P10 | 120 |
| T8 | App B processes the sale of (120 - 20 = 100) | |||
| T9 | App B updates the record P10 | → | P10 | 100 |
To administer locking procedures, a DBMS requires two pieces of information: 1. Whether a particular transaction will update the database; 2. Where the transaction begins and ends.
Usually, the data required by an update transaction are locked when the transaction begins and then released when the transaction is completed (i.e., committed to the database) or aborted. Locking mechanisms can operate at different levels of locking granularity: database, table, page, row, or data element. At the most precise level, a DBMS can lock individual data elements so that different update transactions can update different items in the same record concurrently. This approach increases processing overhead but provides the fewest resource conflicts. At the other end of the continuum, the DBMS can lock the entire database for each update. If there were many update transactions to process, this would be very unacceptable because of the long waiting times. Locking at the record level is the most common approach taken by DBMSs.
In most situations, applications are not concerned with locking, because it is handled entirely by the DBMS. But in some DBMSs, choices are provided to the programmer. These are primarily limited to programming language interfaces.
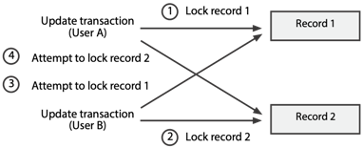
Resource locking solves some data and retrieval integrity problems, but it may lead to another problem, referred to as deadlock or the deadly embrace. Deadlock is an impasse that occurs because two applications lock certain resources, then request resources locked by each other. The following figure illustrates a deadlock situation. Both transactions require records 1 and 2. Transaction A first accesses record 1 and locks it. Then transaction B accesses record 2 and locks it. Next, B’s attempt to access record 1 is denied, so the application waits for the record to be released. Finally, A’s attempt to access record 2 is denied, so the application waits for the record to be released. Thus, application A’s update transaction is waiting for record 2 (locked by application B), and application B is waiting for record 1 (locked by application A). Unless the DBMS intervenes, both applications will wait indefinitely.
There are two ways to resolve deadlock: prevention and resolution. Deadlock prevention requires applications to lock in advance all records they will require. Application B would have to lock both records 1 and 2 before processing the transaction. If these records are locked, B would have to wait.
An example of deadlock
The two-phase locking protocol is a simple approach to preventing deadlocks. It operates on the notion that a transaction has a growing phase followed by a shrinking phase. During the growing phase, locks can be requested. The shrinking phase is initiated by a release statement, which means no additional locks can be requested. A release statement enables the program to signal to the DBMS the transition from requesting locks to releasing locks.
Another approach to deadlock prevention is deadlock resolution, whereby the DBMS detects and breaks deadlocks. The DBMS usually keeps a resource usage matrix, which instantly reflects which applications (e.g., update transactions) are using which resources (e.g., rows). By scanning the matrix, the DBMS can detect deadlocks as they occur. The DBMS then resolves the deadlock by backing out one of the deadlocked transactions. For example, the DBMS might release application A’s lock on record 1, thus allowing application B to proceed. Any changes made by application A up to that time (e.g., updates to record 1) would be rolled back. Application A’s transaction would be restarted when the required resources became available.
Transaction failure and recovery
When a transaction fails, there is the danger of an inconsistent database. Transactions can fail for a variety of reasons, including
Program error (e.g., a logic error in the code)
Action by the transaction manager (e.g., resolution of a deadlock)
Self-abort (e.g., an error in the transaction data means it cannot be completed)
System failure (e.g., an operating-system bug)
If a transaction fails for any reason, then the DBMS must be able to restore the database to a correct state. To do this, two statements are required: an end of transaction (EOT) and commit. EOT indicates the physical end of the transaction, the last statement. Commit, an explicit statement, must occur in the transaction code before the EOT statement. The only statements that should occur between commit and EOT are database writes and lock releases.
When a transaction issues a commit, the transaction manager checks that all the necessary write-record locks for statements following the commit have been established. If these locks are not in place, the transaction is terminated; otherwise, the transaction is committed, and it proceeds to execute the database writes and release locks. Once a transaction is committed, a system problem is the only failure to which it is susceptible.
When a transaction fails, the transaction manager must take one of two corrective actions:
If the transaction has not been committed, the transaction manager must return the database to its state prior to the transaction. That is, it must perform a rollback of the database to its most recent valid state.
If the transaction has been committed, the transaction manager must ensure that the database is established at the correct post-transaction state. It must check that all write statements executed by the transaction and those appearing between commit and EOT have been applied. The DBMS may have to redo some writes.
Protecting existence
One of the three database integrity outcomes is protecting the existence of the database—ensuring data are available when needed. Two strategies for protecting existence are isolation and database backup and recovery. Isolation is a preventive strategy that involves administrative procedures to insulate the physical database from destruction. Some mechanisms for doing this are keeping data in safe places, such as in vaults or underground; having multiple installations; or having security systems. For example, one organization keeps backup copies of important databases on removable magnetic disks. These are stored in a vault that is always guarded. To gain access to the vault, employees need a badge with an encoded personal voice print. Many companies have total-backup computer centers, which contain duplicate databases and documentation for system operation. If something should happen at the main center (e.g., a flood), they can be up and running at their backup center in a few hours, or even minutes in some highly critical situations. What isolation strategies do you use to protect the backup medium of your personal computer? Do you make backup files?
A study of 429 disaster declarations reported to a major international provider of disaster recovery services provides some insights as to the frequency and effects of different IT disasters. These data cover the period 1981–2000 and identify the most frequent disasters and statistics on the length of the disruption.57
Most frequent IT disasters
| Category | Description |
|---|---|
| Disruptive act | Strikes and other intentional human acts, such as bombs or civil unrest, that are designed to interrupt normal organizational processes |
| Fire | Electrical or natural fires |
| IT failure | Hardware, software, or network problems |
| IT move/upgrade | Data center moves and CPU upgrades |
| Natural event | Earthquakes, hurricanes, severe weather |
| Power outage | Loss of power |
| Water leakage | Unintended escape of contained water (e.g., pipe leaks, main breaks) |
Days of disruption per year
| Category | Number | Minimum | Maximum | Mean |
|---|---|---|---|---|
| Natural event | 122 | 0 | 85 | 6.38 |
| IT failure | 98 | 1 | 61 | 6.89 |
| Power outage | 67 | 1 | 20 | 4.94 |
| Disruptive act | 29 | 1 | 97 | 23.93 |
| Water leakage | 28 | 0 | 17 | 6.07 |
| Fire | 22 | 1 | 124 | 13.31 |
| IT move/upgrade | 14 | 1 | 204 | 20.93 |
| Environmental | 6 | 1 | 183 | 65.67 |
| Miscellaneous | 5 | 1 | 416 | 92.8 |
| IT capacity | 2 | 4 | 8 | 6 |
| Theft | 2 | 1 | 3 | 2 |
| Construction | 1 | 2 | 2 | 2 |
| Flood | 1 | 13 | 13 | 13 |
| IT user error | 1 | 1 | 1 | 1 |
Backup and recovery
Database backup and recovery is a curative strategy to protect the existence of a physical database and to recreate or recover the data whenever loss or destruction occurs. The possibility of loss always exists. The use of, and choice among, backup and recovery procedures depends upon an assessment of the risk of loss and the cost of applying recovery procedures. The procedures in this case are carried out by the computer system, usually the DBMS. Data loss and damage should be anticipated. No matter how small the probability of such events, there should be a detailed plan for data recovery.
There are several possible causes for data loss or damage, which can be grouped into three categories.
Storage-medium destruction
In this situation, a portion or all of the database is unreadable as a result of catastrophes such as power or air-conditioning failure, fire, flood, theft, sabotage, and the overwriting of disks or tapes by mistake. A more frequent cause is a disk failure. Some of the disk blocks may be unreadable as a consequence of a read or write malfunction, such as a head crash.
Abnormal termination of an update transaction
In this case, a transaction fails part way through execution, leaving the database partially updated. The database will be inconsistent because it does not accurately reflect the current state of the business. The primary causes of an abnormal termination are a transaction error or system failure. Some operation within transaction processing, such as division by zero, may cause it to fail. A hardware or software failure will usually result in one or more active programs being aborted. If these programs were updating the database, integrity problems could result.
Incorrect data discovered
In this situation, an update program or transaction incorrectly updated the database. This usually happens because a logic error was not detected during program testing.
Because most organizations rely heavily on their databases, a DBMS must provide the following three mechanisms for restoring a database quickly and accurately after loss or damage:
Backup facilities, which create duplicate copies of the database
Journaling facilities, which provide backup copies or an audit trail of transactions or database changes
A recovery facility within the DBMS that restores the database to a consistent state and restarts the processing of transactions
Before discussing each of these mechanisms in more depth, let us review the steps involved in updating a database and how backup and journaling facilities might be integrated into this process.
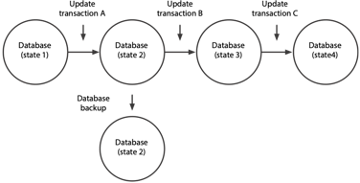
An overview of the database update process is captured in the following figure. The process can be viewed as a series of database state changes. The initial database, state 1, is modified by an update transaction, such as deleting customer Jones, creating a new state (state 2). State 1 reflects the state of the organization with Jones as a customer, while state 2 reflects the organization without this customer. Each update transaction changes the state of the database to reflect changes in organizational data. Periodically, the database is copied or backed up, possibly onto a different storage medium and stored in a secure location. The backup is made when the database is in state 2.
Database state changes as transactions are processed
A more detailed illustration of database update procedures and the incorporation of backup facilities is shown in the following figure.
Possible procedures for a database update
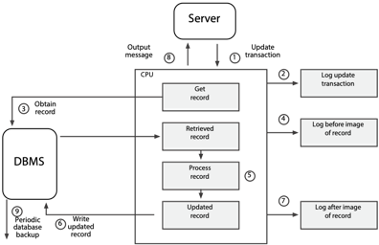
The updating of a single record is described below.
The client submits an update transaction from a workstation.
The transaction is edited and validated by an application program or the DBMS. If it is valid, it is logged or stored in the transaction log or journal. A journal or log is a special database or file that stores information for backup and recovery.
The DBMS obtains the record to be updated.
A copy of the retrieved record is logged to the journal file. This copy is referred to as the before image, because it is a copy of the database record before the transaction changes it.
The transaction is processed by changing the affected data items in the record.
The DBMS writes the updated record to the database.
A copy of the updated record is written to the journal. This copy is referred to as the after image, because it is a copy of the database record after the transaction has updated it.
An output message tells the application that the update has been successfully completed.
The database is copied periodically. This backup copy reflects all updates to the database up to the time when the copy was made. An alternative strategy to periodic copying is to maintain multiple (usually two) complete copies of the database online and update them simultaneously. This technique, known as mirroring, is discussed in Chapter 11.
In order to recover from data loss or damage, it is necessary to store backup data, such as a complete copy of the database or the necessary data to restore the accuracy of a database. Preferably, backup data should be stored on another medium and kept separate from the primary database. As the description of the update process indicates, there are several options for backup data, depending on the objective of the backup procedure.
Backup option
| Objective | Action |
|---|---|
| Complete copy of database | Dual recording of data (mirroring) |
| Past states of the database (also backup known as database dumps) | Database backup |
| Changes to the database | Before-image log or journal |
| After-image log or journal | |
| Transactions that caused a change in the state of the database | Transaction log or journal |
Data stored for backup and recovery are generally some combination of periodic database backups, transaction logs, and before- and after-image logs. Different recovery strategies use different combinations of backup data to recover a database.
The recovery method is highly dependent on the backup strategy. The database administrator selects a strategy based on a trade-off between ease of recovery from data loss or damage and the cost of performing backup operations. For example, keeping a mirror database is more expensive then keeping periodic database backups, but a mirroring strategy is useful when recovery is needed very quickly, say in seconds or minutes. An airline reservations system could use mirroring to ensure fast and reliable recovery. In general, the cost of keeping backup data is measured in terms of interruption of database availability (e.g., time the system is out of operation when a database is being restored), storage of redundant data, and degradation of update efficiency (e.g., extra time taken in update processing to save before or after images).
Recovery strategies
The type of recovery strategy or procedure used in a given situation depends on the nature of the data loss, the type of backup data available, and the sophistication of the DBMS’s recovery facilities. The following discussion outlines four major recovery strategies: switch to a duplicate database, backward recovery or rollback, forward recovery or roll forward, and reprocessing transactions.
The recovery procedure of switching to a duplicate database requires the maintenance of the mirror copy. The other three strategies assume a periodic dumping or backing up of the database. Periodic dumps may be made on a regular schedule, triggered automatically by the DBMS, or triggered externally by personnel. The schedule may be determined by time (hourly, daily, weekly) or by event (the number of transactions since the last backup).
Switching to a duplicate database
This recovery procedure requires maintaining at least two copies of the database and updating both simultaneously. When there is a problem with one database, access is switched to the duplicate. This strategy is particularly useful when recovery must be accomplished in seconds or minutes. This procedure offers good protection against certain storage-medium destruction problems, such as disk failures, but none against events that damage or make both databases unavailable, such as a power failure or a faulty update program. This strategy entails additional costs in terms of doubling online storage capacity. It can also be implemented with dual computer processors, where each computer updates its copy of the database. This duplexed configuration offers greater backup protection at a greater cost.
Backward recovery or rollback
Backward recovery (also called rollback or rolling back) is used to back out or undo unwanted changes to the database. For example, the database update procedures figure shows three updates (A, B, and C) to a database. Let’s say that update B terminated abnormally, leaving the database, now in state 3, inconsistent. What we need to do is return the database to state 2 by applying the before images to the database. Thus, we would perform a rollback by changing the database to state 2 with the before images of the records updated by transaction B.
Backward recovery reverses the changes made when a transaction abnormally terminates or produces erroneous results. To illustrate the need for rollback, consider the example of a budget transfer of $1,000 between two departments.
The program reads the account record for Department X and subtracts $1,000 from the account balance and updates the database.
The program then reads the record for Department Y and adds $1,000 to the account balance, but while attempting to update the database, the program encounters a disk error and cannot write the record.
Now the database is inconsistent. Department X has been updated, but Department Y has not. Thus, the transaction must be aborted and the database recovered. The DBMS would apply the before image to Department X to restore the account balance to its original value. The DBMS may then restart the transaction and make another attempt to update the database.
Forward recovery or roll forward
Forward recovery (also called roll forward or bringing forward) involves recreating a database using a prior database state. Returning to the example in the database update procedures figure, suppose that state 4 of the database was destroyed and that we need to recover it. We would take the last database dump or backup (state 2) and then apply the after-image records created by update transactions B and C. This would return the database to state 4. Thus, roll forward starts with an earlier copy of the database, and by applying after images (the results of good transactions), the backup copy of the database is moved forward to a later state.
Reprocessing transactions
Although similar to forward recovery, this procedure uses update transactions instead of after images. Taking the same example shown above, assume the database is destroyed in state 4. We would take the last database backup (state 2) and then reprocess update transactions B and C to return the database to state 4. The main advantage of using this method is its simplicity. The DBMS does not need to create an after-image journal, and there are no special restart procedures. The one major disadvantage, however, is the length of time to reprocess transactions. Depending on the frequency of database backups and the time needed to get transactions into the identical sequence as previous updates, several hours of reprocessing may be required. Processing new transactions must be delayed until the database recovery is complete.
The following table reviews the three types of data losses and the corresponding recovery strategies one could use. The major problem is to recreate a database using a backup copy, a previous state of organizational memory. Recovery is done through forward recovery, reprocessing, or switching to a duplicate database if one is available. With abnormal termination or incorrect data, the preferred strategy is backward recovery, but other procedures could be used.
What to do when data loss occurs
| Problem | Recovery procedures |
|---|---|
| Storage medium destruction (database is unreadable) | *Switch to a duplicate database—this can be transparent with RAID |
| Forward recovery | |
| Reprocessing transactions | |
| Abnormal termination of an update transaction (transaction recovery error or system failure) | *Backward recovery |
| Forward recovery or reprocessing transactions—bring forward to the state just before termination of the transaction | |
| Incorrect data detected (database has been incorrectly updated) | *Backward recovery |
| Reprocessing transactions has been (excluding those from the update program that created the incorrect data) |
- Preferred strategy
Use of recovery procedures
Usually the person doing a query or an update is not concerned with backup and recovery. Database administration personnel often implement strategies that are automatically carried out by the DBMS. ANSI has defined standards governing SQL processing of database transactions that relate to recovery. Transaction support is provided through the use of the two SQL statements COMMIT and ROLLBACK. These commands are employed when a procedural programming language such as Java is used to update a database. They are illustrated in the chapter on SQL and Java.
❓ Skill builder
An Internet bank with more than 10 million customers has asked for your advice on developing procedures for protecting the existence of its data. What would you recommend?
Maintaining data quality
The second integrity goal is to maintain data quality, which typically means keeping data accurate, complete, and current. Data are high-quality if they fit their intended uses in operations, decision making, and planning. They are fit for use if they are free of defects and possess desired features.58 The preceding definition implicitly recognizes that data quality is determined by the customer. It also implies that data quality is relative to a task. Data could be high-quality for one task and low-quality for another. The data provided by a flight-tracking system are very useful when you are planning to meet someone at the airport, but not particularly helpful for selecting a vacation spot. Defect-free data are accessible, accurate, timely, complete, and consistent with other sources. Desirable features include relevance, comprehensiveness, appropriate level of detail, easy-to-navigate source, high readability, and absence of ambiguity.
Poor-quality data have several detrimental effects. Customer service decreases when there is dissatisfaction with poor and inaccurate information or a lack of appropriate information. For many customers, information is the heart of customer service, and they lose confidence in firms that can’t or don’t provide relevant information. Bad data interrupt information processing because they need to be corrected before processing can continue. Poor-quality data can lead to a wrong decision because inaccurate inferences and conclusions are made.
As we have stated previously, data quality varies with circumstances, and the model in the following figure will help you to understand this linkage. By considering variations in a customer’s uncertainty about a firm’s products and a firm’s ability to deliver consistently, we arrive at four fundamental strategies for customer-oriented data quality.
Customer-oriented data quality strategies
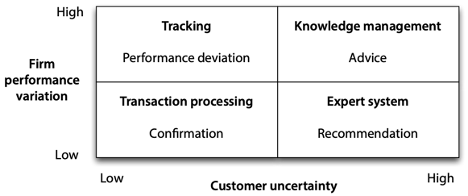
Transaction processing: When customers know what they want and firms can deliver consistently, customers simply want fast and accurate transactions and data confirming details of the transaction. Most banking services fall into this category. Customers know they can withdraw and deposit money, and banks can perform reliably.
Expert system: In some circumstances, customers are uncertain of their needs. For instance, Vanguard offers personal investors a choice from more than 150 mutual funds. Most prospective investors are confused by such a range of choices, and Vanguard, by asking a series of questions, helps prospective investors narrow their choices and recommends a small subset of its funds. A firm’s recommendation will vary little over time because the characteristics of a mutual fund (e.g., intermediate tax-exempt bond) do not change.
Tracking: Some firms operate in environments where they don’t have a lot of control over all the factors that affect performance. One of the busiest airports in the world, Atlanta’s Hartsfield Airport becomes congested when bad weather, such as a summer thunderstorm, slows down operations. Passengers clearly know what they want—data on flight delays and their consequences. They assess data quality in terms of how well data tracks delays and notifies them of alternative travel arrangements.
Knowledge management: When customers are uncertain about their needs for products delivered by firms that don’t perform consistently, they seek advice from knowledgeable people and organizations. Data quality is judged by the soundness of the advice received. Thus, a woman wanting a custom-built house would likely seek the advice of an architect to select the site, design the house, and supervise its construction, because architects are skilled in eliciting clients’ needs and knowledgeable about the building industry.
An organization’s first step toward improving data quality is to determine in which quadrant it operates so it can identify the critical information customers expect. Of course, data quality in many situations will be a mix of expectations. The mutual fund will be expected to confirm fund addition and deletion transactions. However, a firm must meet its dominant goal to attract and retain customers.
A firm will also need to consider its dominant data quality strategy for its internal customers, and the same general principles illustrated by the preceding figure can be applied. In the case of internal customers, there can be varying degrees of uncertainty as to what other organizational units can do for them, and these units will vary in their ability to perform consistently for internal customers. For example, consulting firms develop centers of excellence as repositories of knowledge on a particular topic to provide their employees with a source of expertise. These are the internal equivalent of knowledge centers for external customers.
Once they have settled on a dominant data quality strategy, organizations need a corporate-wide approach to data quality, just like product and service quality. There are three generations of data quality: - First generation: Errors in existing data stores are found and corrected. This data cleansing is necessary when much of the data is captured by manual systems. - Second generation: Errors are prevented at the source. Procedures are put in place to capture high-quality data so that there is no need to cleanse it later. As more data are born digital, this approach becomes more feasible. Thus, when customers enter their own data or barcodes are scanned, the data should be higher-quality than when entered by a data-processing operator. - Third generation: Defects are highly unlikely. Data capture systems meet six-sigma standards (3.4 defects per million), and data quality is no longer an issue.
❓ Skill builder
A consumer electronics company with a well-respected brand offers a wide range of products. For example, it offers nine world-band radios and seven televisions. What data quality strategy would you recommend?
What data quality focus would you recommend for a regulated natural gas utility?
A telephone company has problems in estimating how long it takes to install DSL in homes. Sometimes it takes less than an hour and other times much longer. Customers are given a scheduled appointment and many have to make special arrangements so that they are home when the installation person arrives. What data might these customers
expect from the telephone company, and how would they judge data quality?
Dimensions
The many writers on quality all agree on one thing—quality is multidimensional. Data quality also has many facets, and these are presented in the following table. The list also provides data managers with a checklist for evaluating overall high-quality data. Organizations should aim for a balanced performance across all dimensions because failure in one area is likely to diminish overall data quality.
The dimensions of data quality
| Dimension | Conditions for high-quality data |
|---|---|
| Accuracy | Data values agree with known correct values. |
| Completeness | Values for all reasonably expected attributes are available. |
| Representation consistency | Values for a particular attribute have the same representation across all tables (e.g., dates). |
| Organizational consistency | There is one organization wide table for each entity and one organization wide domain for each attribute. |
| Row consistency | The values in a row are internally consistent (e.g., a home phone number’s area code is consistent with a city’s location). |
| Timeliness | A value’s recentness matches the needs of the most time-critical application requiring it. |
| Stewardship | Responsibility has been assigned for managing data. |
| Sharing | Data sharing is widespread across organizational units. |
| Fitness | The format and presentation of data fit each task for which they are required. |
| Interpretation | Clients correctly interpret the meaning of data elements. |
| Flexibility | The content and format of presentations can be readily altered to meet changing circumstances. |
| Precision | Data values can be conveniently formatted to the required degree of accuracy. |
| International | Data values can be displayed in the measurement unit of choice (e.g., kilometers or miles). |
| Accessibility | Authorized users can readily access data values through a variety of devices from a variety of locations. |
| Security and privacy | Data are appropriately protected from unauthorized access. |
| Continuity | The organization continues to operate in spite of major disruptive events. |
| Granularity | Data are represented at the lowest level necessary to support all uses (e.g., hourly sales). |
| Metadata | There is ready access to accurate data about |
❓ Skill builder
What level of granularity of sales data would you recommend for an online retailer?
What level of data quality completeness might you expect for a university’s student DBMS?
DBMS and data quality
To assist data quality, functions are needed within the DBMS to ensure that update and insert actions are performed by authorized persons in accordance with stated rules or integrity constraints, and that the results are properly recorded. These functions are accomplished by update authorization, data validation using integrity constraints, and concurrent update control. Each of these functions is discussed in turn.
Data validation using integrity constraints
Once the update process has been authorized, the DBMS must ensure that a
database is accurate and complete before any updates are applied.
Consequently, the DBMS needs to be aware of any integrity constraints or
rules that apply to the data. For example, the qdel table in the
relational database described previously would have constraints such as
- Delivery number (
delno) must be unique, numeric, and in the range 1–99999. - Delivered quantity (
delqty) must be nonzero. - Item name (
itemname) must appear in theqitemtable. - Supplier code (
splno) must appear in theqspltable.
Once integrity constraints are specified, the DBMS must monitor or validate all insert and update operations to ensure that they do not violate any of the constraints or rules.
The key to updating data validation is a clear definition of valid and invalid data. Data validation cannot be performed without integrity constraints or rules. A person or the DBMS must know acceptable data format, valid values, and procedures to invoke to determine validity. All data validation is based on a prior expression of integrity constraints.
Data validation may not always produce error-free data, however. Sometimes integrity constraints are unknown or are not well defined. In other cases, the DBMS does provide a convenient means for expressing and performing validation checks.
Based on how integrity constraints have been defined, data validation can be performed outside the DBMS by people or within the DBMS itself. External validation is usually done by reviewing input documents before they are entered into the system and by checking system outputs to ensure that the database was updated correctly. Maintaining data quality is of paramount importance, and data validation preferably should be handled by the DBMS as much as possible rather than by the application, which should handle the exceptions and respond to any failed data validation checks.
Integrity constraints are usually specified as part of the database definition supplied to the DBMS. For example, the primary-key uniqueness and referential integrity constraints can be specified within the SQL CREATE statement. DBMSs generally permit some constraints to be stored as part of the database schema and are used by the DBMS to monitor all update operations and perform appropriate data validation checks. Any given database is likely to be subject to a very large number of constraints, but not all of these can be automatically enforced by the DBMS. Some will need to be handled by application programs.
The general types of constraints applied to a data item are outlined in the following table. Not all of these necessarily would be supported by a DBMS, and a particular database may not use all types.
Types of data items in integrity constraint
| Type of integrity constraint | Explanation | Example |
|---|---|---|
| type | Validating a data item value against a specified data type | Supplier number is numeric. |
| size | Defining and validating the minimum and maximum size of a data item | Delivery number must be at least 3 digits, and at most 5. |
| values | Providing a list of acceptable values for a data item | Item colors must match the list provided. |
| range | Providing one or more ranges within which the data item must lie | Employee numbers must be in the range 1–100. |
| pattern | Providing a pattern of allowable characters that define permissible formats for data values | Department phone number must be of the form 542-nnnn (stands for exactly four decimal digits). |
| procedure | Providing a procedure to be invoked to validate data items | A delivery must have valid item name, department, and supplier values before it can be added to the database (tables are checked for valid entries). |
| Conditional | Providing one or more conditions to apply against data values | If item type is “Y,” then color is null. |
| Not null (mandatory) | Indicating whether the data item value is mandatory (not null) or optional; the not-null option is required for primary keys | Employee number is mandatory. |
| Unique | Indicating whether stored values for this data item must be compared to other values of the item within the same table | Supplier number is unique. |
As mentioned, integrity constraints are usually specified as part of the database definition supplied to the DBMS. The following example contains typical specifications of integrity constraints for a relational DBMS.
Example
CREATE TABLE stock (
stkcode CHAR(3),
…,
natcode CHAR(3),
PRIMARY KEY(stkcode),
CONSTRAINT fk_stock_nation
FOREIGN KEY(natcode)
REFERENCES nation(natcode)
ON DELETE RESTRICT);Explanation
Column stkcode must always have 3 or fewer alphanumeric characters, and stkcode must be unique because it is a primary key.
Column natcode must be assigned a value of 3 or less alphanumeric characters and must exist as the primary key of the nation.
Do not allow the deletion of a row in nation while there still exist rows in stock containing the corresponding value of natcode.
Data quality control does not end with the application of integrity constraints. Whenever an error or unusual situation is detected by the DBMS, some form of response is required. Response rules need to be given to the DBMS along with the integrity constraints. The responses can take many different forms, such as abort the entire program, reject entire update transaction, display a message and continue processing, or let the DBMS attempt to correct the error. The response may vary depending on the type of integrity constraint violated. If the DBMS does not allow the specification of response rules, then it must take a default action when an error is detected. For example, if alphabetic data are entered in a numeric field, most DBMSs will have a default response and message (e.g., nonnumeric data entered in numeric field). In the case of application programs, an error code is passed to the program from the DBMS. The program would then use this error code to execute an error-handling procedure.
Ensuring confidentiality
Thus far, we have discussed how the first two goals of data integrity can be accomplished: Data are available when needed (protecting existence); data are accurate, complete, and current (maintaining quality). This section deals with the final goal: ensuring confidentiality or data security. Two DBMS functions—access control and encryption—are the primary means of ensuring that the data are accessed only by those authorized to do so. We begin by discussing an overall model of data security.
General model of data security
The following figure depicts the two functions for ensuring data confidentiality: access control and encryption. Access control consists of two basic steps—identification and authorization. Once past access control, the user is permitted to access the database. Access control is applied only to the established avenues of entry to a database. Clever people, however, may be able to circumvent the controls and gain unauthorized access. To counteract this possibility, it is often desirable to hide the meaning of stored data by encrypting them, so that it is impossible to interpret their meaning. Encrypted data are stored in a transformed or coded format that can be decrypted and read only by those with the appropriate key.
A general model of data security
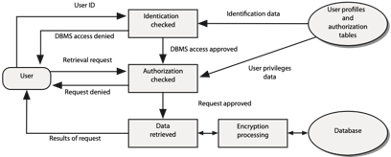
Now let us walk through the figure in detail.
A client must be identified and provide additional information required to authenticate this identification (e.g., an account name and password). Client profile information (e.g., a password or a voice print) is used to verify or authenticate a connection.
Having authenticated the client, the authorization step is initiated by a request (retrieve or update database). The previously stored client authorization rules (what data each client can access and the authorized actions on those data) are checked to determine whether the client has the right or privilege to access the requested data. (The previously stored client’s privileges are created and maintained by an authorized person, database owner, or administrator.) A decision is made to permit or deny the execution of the request. If access is permitted, the transaction is processed against the database.
Data are encrypted before storage, and retrieved data are decrypted before presentation.
Data access control
Data access control begins with identification of an organizational entity that can access the database. Examples are individuals, departments, groups of people, transactions, terminals, and application programs. Valid combinations may be required, for example, a particular person entering a certain transaction at a particular terminal. A user identification (often called userid) is the first piece of data the DBMS receives from the subject. It may be a name or number. The user identification enables the DBMS to locate the corresponding entry in the stored user profiles and authorization tables (see preceding figure).
Taking this information, the DBMS goes through the process of authentication. The system attempts to match additional information supplied by the client with the information previously stored in the client’s profile. The system may perform multiple matches to ensure the identity of the client (see the following table for the different types). If all tests are successful, the DBMS assumes that the subject is an authenticated client.
Authenticating mechanisms1
| Class | Examples |
|---|---|
| Something a person knows: remembered information | Name, account number, password |
| Something the person has: possessed object | Badge, plastic card, key |
| Something the person is: personal characteristic | Fingerprint, voiceprint, signature, hand size |
Many systems use remembered information to control access. The problem with such information is that it does not positively identify the client. Passwords have been the most widely used form of access control. If used correctly, they can be very effective. Unfortunately, people leave them around where others can pick them up, allowing unauthorized people to gain access to databases.
To deal with this problem, organizations are moving toward using personal characteristics and combinations of authenticating mechanisms to protect sensitive data. Collectively, these mechanisms can provide even greater security. For example, access to a large firm’s very valuable marketing database requires a smart card and a fingerprint, a combination of personal characteristic and a possessed object. The database can be accessed through only a few terminals in specific locations, an isolation strategy. Once the smart card test is passed, the DBMS requests entry of other remembered information—password and account number—before granting access.
Data access authorization is the process of permitting clients whose identity has been authenticated to perform certain operations on certain data objects in a shared database. The authorization process is driven by rules incorporated into the DBMS. Authorization rules are in a table that includes subjects, objects, actions, and constraints for a given database. An example of such a table is shown in the following table. Each row of the table indicates that a particular subject is authorized to take a certain action on a database object, perhaps depending on some constraint. For example, the last entry of the table indicates that Brier is authorized to delete supplier records with no restrictions.
Sample authorization table
| Subject/Client | Action | Object | Constraint |
|---|---|---|---|
| Accounting department | Insert | Supplier table | None |
| Purchase department clerk | Insert | Supplier table | If quantity < 200 |
| Purchase department supervisor | Insert | Delivery table | If quantity >= 200 |
| Production department | Read | Delivery table | None |
| Todd | Modify | Item table | Type and color only |
| Order-processing program | Modify | Sale table | None |
| Brier | Delete | Supplier table | None |
We have already discussed subjects, but not objects, actions, and constraints. Objects are database entities protected by the DBMS. Examples are databases, views, files, tables, and data items. In the preceding table, the objects are all tables. A view is another form of security. It restricts the client’s access to a database. Any data not included in a view are unknown to the client. Although views promote security, several persons may share a view or unauthorized persons may gain access. Thus, a view is another object to be included in the authorization process. Typical actions on objects are shown in the table: read, insert, modify, and delete. Constraints are particular rules that apply to a subject-action-object relationship.
Encryption
Encryption techniques complement access control. As the preceding figure illustrates, access control applies only to established avenues of access to a database. There is always the possibility that people will circumvent these controls and gain unauthorized access to a database. To counteract this possibility, encryption can be used to obscure or hide the meaning of data. Encrypted data cannot be read by an intruder unless that person knows the method of encryption and has the key. Encryption is any transformation applied to data that makes it difficult to extract meaning. Encryption transforms data into cipher text or disguised information, and decryption reconstructs the original data from cipher text.
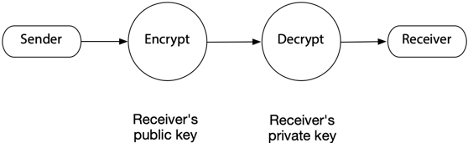
Public-key encryption is based on a pair of private and public keys. A person’s public key can be freely distributed because it is quite separate from his or her private key. To send and receive messages, communicators first need to create private and public keys and then exchange their public keys. The sender encodes a message with the intended receiver’s public key, and upon receiving the message, the receiver applies her private key. The receiver’s private key, the only one that can decode the message, must be kept secret to provide secure message exchanging.
Public-key encryption
In a DBMS environment, encryption techniques can be applied to transmitted data sent over communication lines to and from devices, or between computers, and to all highly sensitive stored data in active databases or their backup versions. Some DBMS products include routines that automatically encrypt sensitive data when they are stored or transmitted over communication channels. Other DBMS products provide exits that allow users to code their own encryption routines. Encrypted data may also take less storage space because they are often compressed.
❓Skill builder
A university has decided that it will e-mail students their results at the end of each semester. What procedures would you establish to ensure that only the designated student opened and viewed the e-mail?
Monitoring activity
Sometimes no single activity will be detected as an example of misuse of a system. However, examination of a pattern of behavior may reveal undesirable behavior (e.g., persistent attempts to log into a system with a variety of userids and passwords). Many systems now monitor all activity using audit trail analysis. A time- and date-stamped audit trail of all system actions (e.g., database accesses) is maintained. This audit log is dynamically analyzed to detect unusual behavior patterns and alert security personnel to possible misuse.
A form of misuse can occur when an authorized user violates privacy rules by using a series of authorized queries to gain access to private data. For example, some systems aim to protect individual privacy by restricting authorized queries to aggregate functions (e.g., AVG and COUNT). Since it is impossible to do non-aggregate queries, this approach should prevent access to individual-level data, which it does at the single-query level. However, multiple queries can be constructed to circumvent this restriction.
Assume we know that a professor in the IS department is aged 40 to 50, is single, and attended the University of Minnesota. Consider the results of the following set of queries.59
| 10 |
SELECT COUNT(*) FROM faculty
WHERE dept = 'MIS'
AND age >= 40 AND age <= 50
AND degree_from = 'Minnesota';| 2 |
SELECT COUNT(*) FROM faculty
WHERE = 'MIS'
AND age >= 40 AND age <= 50;
AND degree_from = 'Minnesota'
AND marital_status = 'S';| 1 |
SELECT AVG(salary) FROM faculty
WHERE dept = 'MIS'
AND age >= 40 AND age <= 50
AND degree_from = 'Minnesota'
AND marital_status = 'S';| 85000 |
The preceding set of queries, while all at the aggregate level, enables one to deduce the salary of the professor. This is an invasion of privacy and counter to the spirit of the restriction queries to aggregate functions. An audit trail should detect such tracker queries, one or more authorized queries that collectively violate privacy. One approach to preventing tracker queries is to set a lower bound on the number of rows on which a query can report.
Summary
The management of organizational data is driven by the joint goals of availability and integrity. Availability deals with making data available to whoever needs them, whenever and wherever they need them, and in a meaningful form. Maintaining integrity implies protecting existence, maintaining quality, and ensuring confidentiality. There are three strategies for maintaining data integrity: legal, administrative, and technical. A consistent database is one in which all data integrity constraints are satisfied.
A transaction must be entirely completed or aborted before there is any effect on the database. Transactions are processed as logical units of work to ensure data integrity. The transaction manager is responsible for ensuring that transactions are correctly recorded.
Concurrent update control focuses on making sure updated results are correctly recorded in a database. To prevent loss of updates and inconsistent retrieval results, a DBMS must incorporate a resource-locking mechanism. Deadlock is an impasse that occurs because two users lock certain resources, then request resources locked by each other. Deadlock prevention requires applications to lock all required records at the beginning of the transaction. Deadlock resolution uses the DBMS to detect and break deadlocks.
Isolation is a preventive strategy that involves administrative procedures to insulate the physical database from destruction. Database backup and recovery is a curative strategy that protects an existing database and recreates or recovers the data whenever loss or destruction occurs. A DBMS needs to provide backup, journaling, and recovery facilities to restore a database to a consistent state and restart the processing of transactions. A journal or log is a special database or file that stores information for backup and recovery. A before image is a copy of a database record before a transaction changes the record. An after image is a copy of a database record after a transaction has updated the record.
In order to recover from data loss or damage, it is necessary to store redundant, backup data. The recovery method is highly dependent on the backup strategy. The cost of keeping backup data is measured in terms of interruption of database availability, storage of redundant data, and degradation of update efficiency. The four major recovery strategies are switching to a duplicate database, backward recovery or rollback, forward recovery or roll forward, and reprocessing transactions. Database administration personnel often implement recovery strategies automatically carried out by the DBMS. The SQL statements COMMIT and ROLLBACK are used with a procedural programming language for implementing recovery procedures.
Maintaining quality implies keeping data accurate, complete, and current. The first step is to ensure that anyone wanting to update a database is required to have authorization. In SQL, access control is implemented through GRANT and REVOKE. Data validation cannot be performed without integrity constraints or rules. Data validation can be performed external to the DBMS by personnel or within the DBMS based on defined integrity constraints. Because maintaining data quality is of paramount importance, it is desirable that the DBMS handles data validation rather than the application. Error response rules need to be given to the DBMS along with the integrity constraints.
Two DBMS functions, access control and encryption, are the primary mechanisms for ensuring that the data are accessed only by authorized persons. Access control consists of identification and authorization. Data access authorization is the process of permitting users whose identities have been authenticated to perform certain operations on certain data objects. Encrypted data cannot be read by an intruder unless that person knows the method of encryption and has the key. In a DBMS environment, encryption can be applied to data sent over communication lines between computers and data storage devices.
Database activity is monitored to detect patterns of activity indicating misuse of the system. An audit trail is maintained of all system actions. A tracker query is a series of aggregate function queries designed to reveal individual-level data.
Key terms and concepts
| ACID | Integrity constraint |
| Administrative strategies | Isolation |
| After image | Journal |
| All-or-nothing rule | Legal strategies |
| Atomicity | Locking |
| Audit trail analysis | Maintaining quality |
| Authentication | Private key |
| Authorization | Protecting existence |
| Backup | Public-key encryption |
| Before image | Recovery |
| COMMIT | Reprocessing |
| Concurrent update control | REVOKE |
| Consistency | Roll forward |
| Data access control | ROLLBACK |
| Data availability | Rollback |
| Data quality | Serializability |
| Data security | Slock |
| Database integrity | Technical strategies |
| Deadlock prevention | Tracker query |
| Deadlock resolution | Transaction |
| Deadly embrace | Transaction atomicity |
| Decryption | Transaction manager |
| Durability | Two-phase locking protocol |
| Encryption | Validation |
| Ensuring confidentiality | Xlock |
| GRANT |
Exercises
What are the three goals of maintaining organizational memory integrity?
What strategies are available for maintaining data integrity?
A large corporation needs to operate its computer system continuously to remain viable. It currently has data centers in Miami and San Francisco. Do you have any advice for the CIO?
An investment company operates out of a single office in Boston. Its business is based on many years of high-quality service, honesty, and reliability. The CEO is concerned that the firm has become too dependent on its computer system. If some disaster should occur and the firm’s databases were lost, its reputation for reliability would disappear overnight and so would many of its customers in this highly competitive business. What should the firm do?
What mechanisms should a DBMS provide to support backup and recovery?
What is the difference between a before image and an after image?
A large organization has asked you to advise on backup and recovery procedures for its weekly, batch payroll system. They want reliable recovery at the lowest cost. What would you recommend?
An online information service operates globally and prides itself on its uptime of 99.98 percent. What sort of backup and recovery scheme is this firm likely to use? Describe some of the levels of redundancy you would expect to find.
The information systems manager of a small manufacturing company is considering the backup strategy for a new production planning database. The database is used every evening to create a plan for the next day’s production. As long as the production plan is prepared before 6 a.m. the next day, there is no impact upon plant efficiency. The database is currently 200 Mbytes and growing about 2 percent per year. What backup strategy would you recommend and why?
How do backward recovery and forward recovery differ?
What are the advantages and disadvantages of reprocessing transactions?
When would you use ROLLBACK in an application program?
When would you use COMMIT in an application program?
Give three examples of data integrity constraints.
What is the purpose of locking?
What is the likely effect on performance between locking at a row compared to locking at a page?
What is a deadly embrace? How can it be avoided?
What are three types of authenticating mechanisms?
Assume that you want to discover the grade point average of a fellow student. You know the following details of this person. She is a Norwegian citizen who is majoring in IS and minoring in philosophy. Write one or more aggregate queries that should enable you to determine her GPA.
What is encryption?
What are the disadvantages of the data encryption standard (DES)?
What are the advantages of public-key encryption?
A national stock exchange requires listed companies to transmit quarterly reports to its computer center electronically. Recently, a hacker intercepted some of the transmissions and made several hundred thousand dollars because of advance knowledge of one firm’s unexpectedly high quarterly profits. How could the stock exchange reduce the likelihood of this event?
To the author’s knowledge, Gordon C. Everest was the first to define data integrity in terms of these three goals. See Everest, G. (1986). Database management: objectives, systems functions, and administration. New York, NY: McGraw-Hill.↩︎
Source: Lewis Jr, W., Watson, R. T., & Pickren, A. (2003). An empirical assessment of IT disaster probabilities. Communications of the ACM, 46(9), 201-206.↩︎
Redman, T. C. (2001). Data quality : the field guide. Boston: Digital Press.↩︎
Adapted from Helman, P. (1994). The science of database management. Burr Ridge, IL: Richard D. Irwin, Inc. p. 434↩︎