
The university architect has asked you to develop a data model to record details of the campus buildings. A building can have many rooms, but a room can be in only one building. Buildings have names, and rooms have a size and purpose (e.g., lecture, laboratory, seminar). Draw a data model for this situation and create the matching relational database.
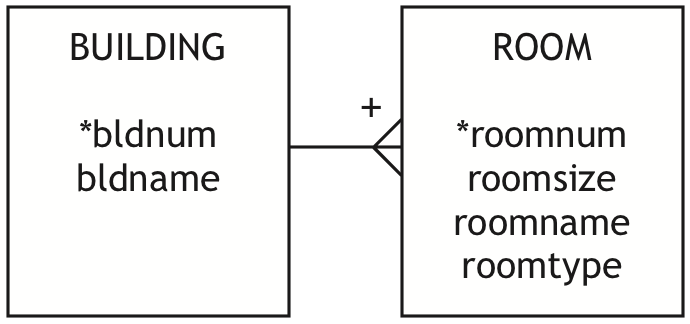
CREATE TABLE building ( bldnum INTEGER, bldname CHAR(20), PRIMARY KEY(bldnum)); CREATE TABLE ROOM ( roomnum INTEGER, roomsize INTEGER, roomname CHAR(20), roomtype CHAR(20), bldnum INTEGER, PRIMARY KEY (roomnum, bldnum), CONSTRAINT fkbuilding FOREIGN KEY(bldnum) REFERENCES building);
Report by nation the total value of dividends.
SELECT natname, SUM(stkqty*stkdiv) FROM nation JOIN stock ON stock.natcode = nation.natcode GROUP BY natname;
1. Why are no India stocks reported in the correlated subquery example? How would you change the query to report an Indian stock?
There is only one Indian stock and the query specifies "greater than the average," and thus the average for Indian is the holding of that stock, which is equal to the average. By changing the query to "greater than or equal to the average," the Indian stock will be reported.
SELECT natname, stkfirm, stkqty from stock JOIN nation ON stock.natcode = nation.natcode WHERE stkqty >= (SELECT AVG(stkqty) FROM stock WHERE stock.natcode = nation.natcode);
2. Report only the three stocks with the largest quantities (i.e., do the query without using order by).
SELECT stkfirm, stkqty FROM stock stk1 WHERE (SELECT COUNT(*) FROM stock stk2 WHERE stk2.stkqty >= stk1.stkqty) < 4;
This is a challenging correlated query to understand, as most correlated queries are. First, you create two temporary copies of stock , which are called stk1 and stk2 (stock stk1 specifies creation of a temporary copy of stock that is called stk1). The inner part of the correlated query takes one row of stk1 at a time and counts how many rows in stk2 have a value of stkqty greater than or equal to the value of stkqty for the current stk1 row. If the count is less than 4, then the row is reported. In other words, if for any row of stock there are fewer than four other rows in stock with a greater or equal value of stkqty, then this row must have one of the three largest values of stkqty.
A student contributed the following solution. The solution shows mastery of SQL, but it is not as generalized as the previous answer. For example, what if the request is for the five stocks with the largest quantities?
SELECT * FROM stock WHERE
stkqty >= (SELECT MAX(stkqty) FROM stock
WHERE stkqty < (SELECT MAX(stkqty) FROM stock
WHERE stkqty < (SELECT MAX(stkqty) FROM stock)))
ORDER BY stkqty DESC;
How could you use a view to solve the following query that was used when discussing the correlated subquery?
Find those stocks where the quantity is greater than the average for that country.
CREATE VIEW natavg AS (SELECT natcode, AVG(stkqty)as avgstkqty FROM stock GROUP BY natcode); SELECT stkfirm, stock.natcode FROM stock JOIN natavg
ON stock.natcode = natavg.natcode
WHERE stock.stkqty > natavg.avgstkqty;
Create tables to store the label and CD data. Add a column to track to store the foreign key. Then, either enter the new data or download it from the Web site. Define lbltitle as a foreign key in cd and cdid as a foreign key in track.
1a. List the tracks by CD in order of track length.
SELECT cdtitle, trktitle, trklength FROM cd JOIN track
ON track.cdid = cd.cdid
ORDER BY cdtitle, trklength;
1b. What is the longest track on each CD?
SELECT track.cdid,trktitle, trklength FROM cd JOIN track
ON trklength =
(SELECT MAX(trklength) FROM track
WHERE track.cdid = cd.cdid);
2. What is wrong with the current data model?
There is still some important information missing:
Since every label has its own system of assigning IDs to their own CDs, there is some possibility that two labels will use the same ID for two different CDs.
This page is part of the promotional and support material for Data Management (open edition) by Richard T. Watson |